

What it means, how...it sounds
Linking the linguistics puzzles of syntax and prosody
Language gets its sentence structure from syntax. The syntax of English, for example, dictates that the sentence “The dog ate the pie”—that is, a word order of subject-verb-object—is grammatically correct, while “The dog the pie ate”—subject-object-verb—is not. But on top of the grammatical rules of syntax, language is also defined by its sound and rhythmic structure. Linguists refer to this spoken cadence as “prosody,” and it describes how we group syllables and words in speech. For example, in English we generally say, “The dog [pause] ate the pie,” rather than, “The dog ate [pause] the pie.”
Linguists have generally studied these two dimensions of language separately, but there is growing interest in how they intersect, said Junko Ito, UC Santa Cruz professor of linguistics. Syntax provides the basic structure, the traditional thinking goes, and prosody defines how it sounds in its spoken version. Yet while the word groupings in syntax differ from the emphasis groupings of prosody, they are clearly related, said Armin Mester, Ito’s close collaborator and UCSC professor emeritus of linguistics. “The question is, how do these two different structures link?”
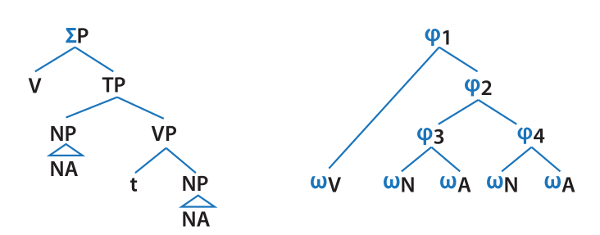
Ito and Mester helped pioneer early work on this question in the 1990s, when they began studying how syntax and prosody interact in Japanese. Since then, the UCSC Linguistics Department’s momentum in this field, called the “syntax-prosody interface,” has snowballed, with the research including studies of German, Basque, Latin, several Mayan languages, and others. “We have a reputation for being one of the handful of places globally where people really understand this area of linguistic research,” said Ryan Bennett, assistant professor of linguistics and another member of the UCSC group working in this area.
Bennett, along with UCSC professor emeritus Jim McCloskey and Emily Elfner, assistant professor of linguistics at York University in Toronto, studies the sentence position of pronouns in Irish. In Irish, unlike in English, the basic word order is verb-subject-object, with any additional words tacked on at the end, Bennett said. “But when the object is a pronoun you can put it in all sorts of crazy places in the sentence.”

Bennett and colleagues theorized that pronouns and other small words in Irish tend to drift rightward, to the end of a sentence, because their position toward the beginning “would be sort of counter-rhythmic, given the intonational structure of the language,” Bennett said. That means that rather than syntax determining prosody, in this case prosody drives syntax—an idea that’s counter-intuitive in the field, he said.
To truly understand the rules governing the syntax-prosody interface, Bennett and other UCSC linguists think that researchers will have to systematically explore how prosodic groupings form in as many languages as possible. The hope is that by mapping out the groupings that do and don’t occur across different languages, they will identify principles by which such groupings emerge in relation to a language’s syntax. “Linguistic theory needs to have an explanation for what is possible, and what is not,” Ito said.
That’s a daunting task, however, because the possibilities are nearly limitless. For a sentence with two words, for example, you’d have eight structures—each word can be a prosodic phrase by itself, or not (four structures), and each of these four structures has a variant in which the whole sequence is a phonological phrase. But once you have five or more words, there are thousands of structures. “It really is exponential, and you cannot think of all these yourself,” Mester said. To address this problem of scale, linguistics graduate student Jenny Bellik and postdoc and lecturer Nick Kalivoda built a computer program called “SPOT” (for Syntax-Prosody in Optimality Theory) that methodically assesses possible word groupings in different languages. “Initial work in this area didn’t need computers, but as it has grown, the automation is essential,” Mester said.
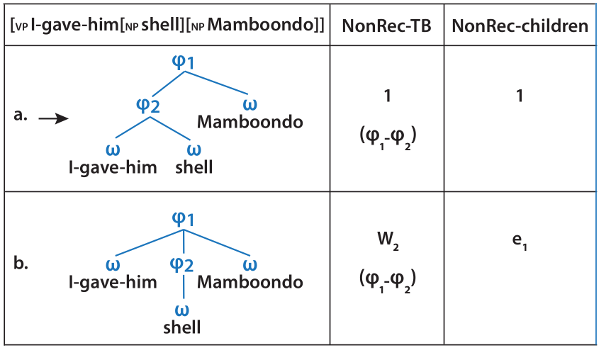
In December of last year, Ito and Mester received a two-year, $250,000 grant from the National Science Foundation to improve SPOT, making it more user-friendly, and to introduce it to a wider audience through symposia and conferences. Although now primarily used for academic research, the software could ultimately spawn commercial projects in natural language processing and speech recognition, Ito said.
It has already yielded important linguistic insights. For example, SPOT analyses performed by the UCSC team in collaboration with Gorka Elordieta, UCSC visiting associate professor and associate professor at the University of the Basque Country, revealed similarities between Basque and Japanese that could not have been predicted otherwise. But another key benefit to SPOT, said Bennett, reflects the spirit of innovation and inclusivity within the UCSC Linguistics Department. “It provides an entry-point for everyone, from undergraduates to grad students to faculty,” he said. “People can learn and contribute on all sorts of different levels.”